Jensen Huang opened GTC Taipei at Computex 2026 on the keynote stage at the Taipei Music Center with the largest single-keynote product drop NVIDIA has done in years[1]. By the time the lights came up there were eleven new silicon SKUs, a fresh foundation-model family, a refreshed robotics platform with a reference humanoid built on it, two new runtime stories for autonomous agents, a full media stack, and a global mobility platform. This is the recap for the open-source AI engineer trying to decide where to put the next six months of effort.
If you only have a minute, take these.
- Vera Rubin NVL72 is in full production. Assembly time for a Grace Blackwell rack dropped to five minutes. NVIDIA quotes 10× higher inference performance per watt and 10× lower cost per token versus the previous generation[1].
- RTX Spark and the new DGX Station refresh make personal AI compute real on Windows. RTX Spark is the chip; DGX Station GB300 is the deskside box with 748GB coherent memory and up to 20 petaflops FP4[6].
- Cosmos 3 turned up with an actual reference humanoid. Isaac GR00T sits on top of Jetson Thor. The robotics story is no longer aspirational[9][10][11].
- Nemotron 3 Ultra is a 550-billion-parameter mixture-of-experts open model. NVIDIA quotes ~5× faster inference and ~30% cheaper running cost than the leading proprietary models[12].
- The Agent Toolkit plus OpenShell runtime is NVIDIA's enterprise agent play. Skip if you build OSS; useful to mention if you sell to enterprise.
- NVIDIA AI for Media is the surprise package. LipSync, Active Speaker Detection, Synthetic Video Detector at roughly 92% accuracy in roughly 22 milliseconds. Practical primitives for broadcasters.
The rest of this post unpacks each of those.

Vera Rubin NVL72 is in full production
Vera Rubin NVL72 is the rack-scale system that ties 36 Vera CPUs and 72 Rubin GPUs together with NVLink Switch and Spectrum-X Ethernet Photonics. NVIDIA's published figures put it at 10× higher inference performance per watt and 10× lower cost per token versus the prior generation[1][5]. The most operationally interesting line on stage was that the Grace Blackwell rack assembly time has been reduced to five minutes per rack, which has supply-chain implications more than performance ones.

The interpretation for the open-source AI engineer is the same as the Blackwell pattern. The price-per-hour on third-party Rubin rentals will lag the throughput improvement by months. Cloud providers buy at scale and price for amortisation. The bookend you care about is when the cheapest Rubin hour on Lambda, RunPod, Modal, or your preferred fallback provider drops below the H100 hour you are paying for today. That is the moment your hosting cost actually falls. For workloads with heavy paged-KV pressure (voice loops, agent swarms) the win is larger than for long-prompt one-shot summarisation.
For my own forge-infer work[13], NVIDIA's confirmation that paged KV plus continuous batching plus speculative decoding is the production baseline matters because it means the design choices in the repo are aligned with the production-grade stack. The differences are throughput at scale and ecosystem maturity, not architecture.
Vera CPU and BlueField-4 STX: the parts you do not directly buy
Vera CPU is an 88-core agent-runtime-targeted CPU with 1.2TB/s LPDDR5X bandwidth and a 3.6TB/s on-chip fabric. BlueField-4 STX is the storage and security DPU paired with it; the keynote highlighted DOCA Argus cutting threat detection from minutes to milliseconds[1]. Neither product is something an indie open-source AI engineer buys directly. They matter because they shape the cost-per-hour of the rented machine you do buy.
What you do is keep your gateway in the middle. Sarmalink-AI's adapter pattern treats a Vera Rubin instance behind a third-party provider as exactly the same upstream as any other. The day Lambda or CoreWeave lists a Vera Rubin tier, the rotation policy adds it and the cost-aware router picks it for the right workload[14].
RTX Spark and DGX Station GB300: personal AI compute, finally, on Windows
This was the announcement that mattered most to me, and the one with the cleanest implications for local-first assistant work.
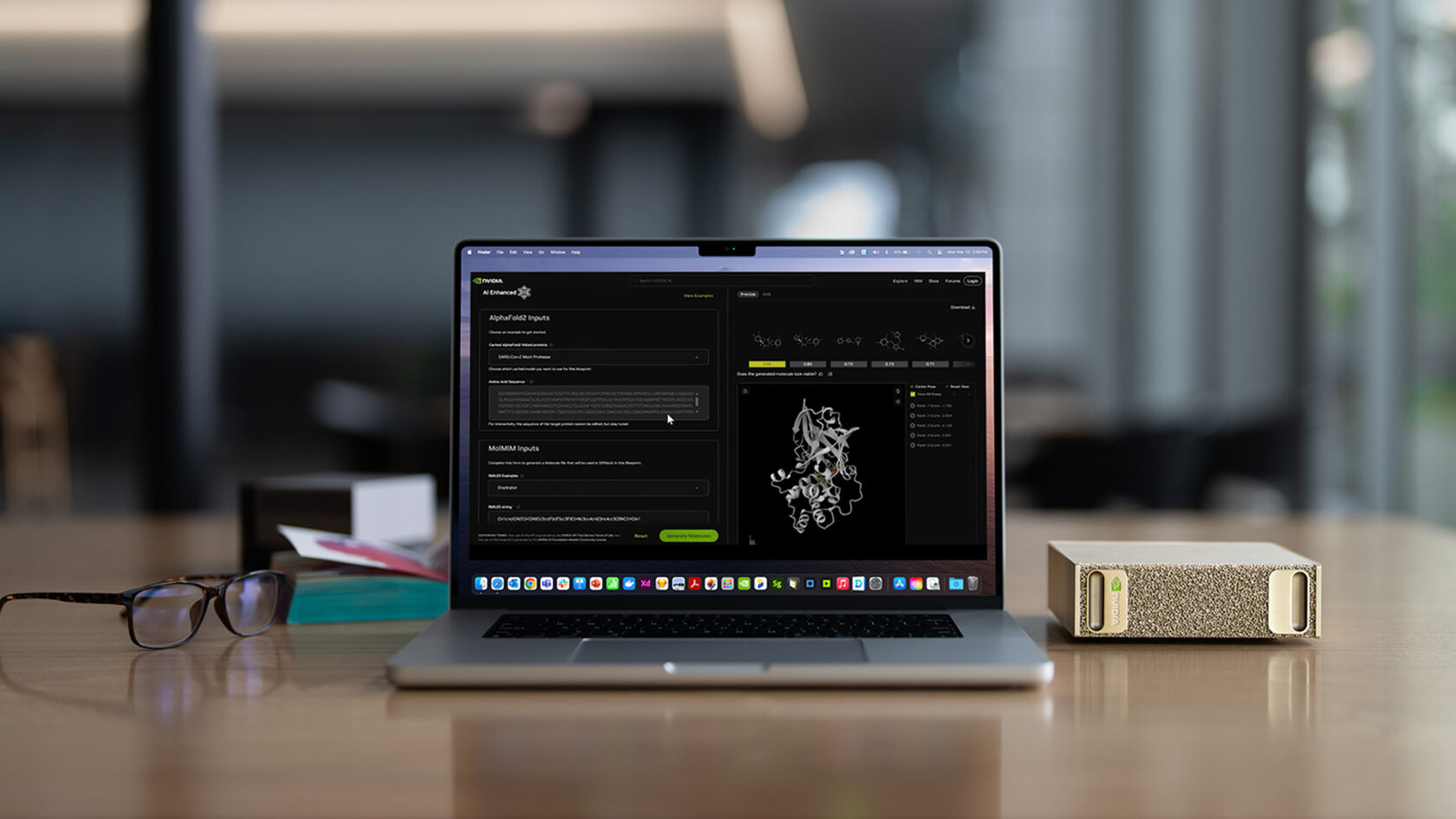
RTX Spark is the chip. NVIDIA describes it as 1 petaflop of AI performance, pairing a Blackwell RTX GPU (6,144 CUDA cores) with a custom 20-core Grace CPU. The whole point is that the full NVIDIA software stack runs on it, including the model formats and the runtime, so the developer experience does not change between a workstation and a data centre[1][6].
DGX Station GB300 is the deskside box. It carries 748GB of coherent memory and up to 20 petaflops FP4 throughput, with NVIDIA explicitly pitching it for frontier-scale models up to 1 trillion parameters. A separate DGX Station for Windows configuration targets enterprise Windows developers and "always-on" agents.

Why an open-source AI engineer cares.
- Local-first assistants[16] suddenly have a credible inference platform on Windows. echo, the open Jarvis I am shipping on 1 July, runs on whichever AI subscription you authorise. The fully-local path uses Ollama or LM Studio against any model you can fit on your hardware. A trillion-parameter model on a deskside box is a different conversation than a 7B model on a MacBook.
- The voice loop[15] gets a clean home. Sub-second turn time on a 30B-or-larger brain, running fully on-device, is now a single-box hardware decision rather than a fleet decision.
- The "private" production path got cheaper. For teams that have to keep prompts inside the building (legal, healthcare, defence), a small fleet of DGX Station GB300s is now competitive with the equivalent rental hours on hyperscalers.
NVIDIA's framing of "personal AI compute" was on the nose this year. The hardware is real and the price is fair. The question for the open-source community is who builds the software stack that makes a DGX Spark feel like a Mac Studio fifteen minutes after unboxing. That is, more or less, what I am building Echo for.

Cosmos 3 and Isaac GR00T: robotics is closer than it looks
The least-expected substantive announcement was Cosmos 3, the new generation of NVIDIA's World Foundation Models for physical AI. The framing last year was aspirational. This year's demonstrations were not. Three patterns make Cosmos suddenly relevant to the broader AI engineering field.
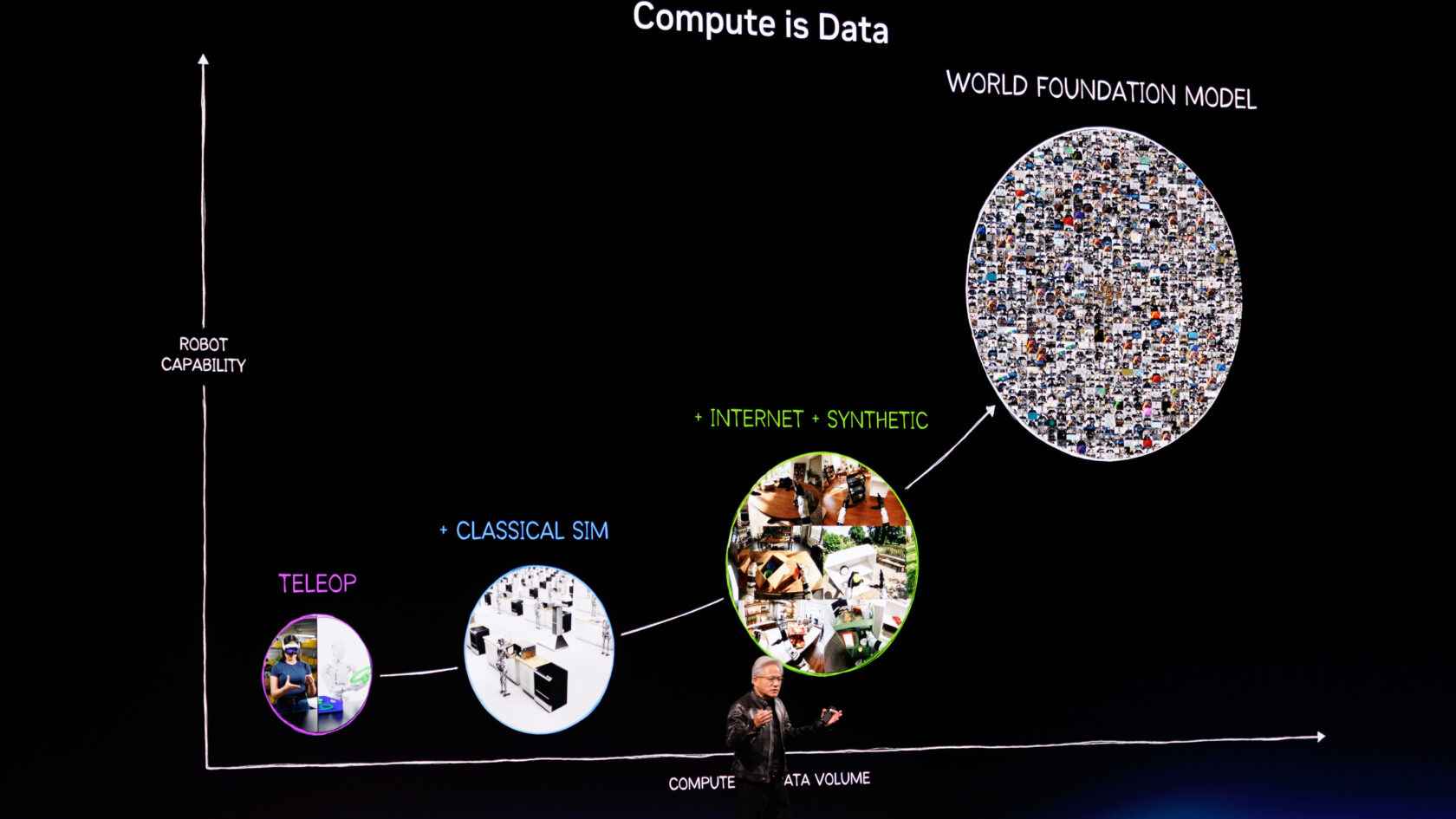
- It is an MCP-shape skill catalog by default. The Cosmos runtime exposes the robot's capabilities (move base, grip object, perceive scene) through a tool catalog that maps cleanly onto the Model Context Protocol. Any LLM that speaks MCP can drive a Cosmos-compatible robot.
- Simulation-first deployment is realistic. You can develop and test the agent loop in NVIDIA Omniverse against a simulated robot, then deploy the same agent loop against a real one. The provenance story resembles what Temporal-backed agents look like on the web today.
- The brain stays in your control. The Cosmos surface is brain-agnostic. You can drive it with Claude, GPT, Gemini, an open-weight model on a DGX Spark, anything that speaks MCP. NVIDIA does not insist you use their LLM.
Stacked on top of Cosmos 3, NVIDIA unveiled Isaac GR00T, the first open humanoid reference design, built on Jetson Thor[10][11]. Jetson Thor itself delivers 2,070 FP4 teraflops in a configurable 40-to-130-watt envelope and is positioned for robots, industrial systems, medical devices, and autonomous machines.
For the open-source AI engineer who does not work on robots, the relevant takeaway is that Cosmos plus a multi-provider gateway[14] plus an agent orchestrator is the entire shape of embodied agents in 2027. Anyone shipping in the agent runtime space should at least read the Cosmos developer guide once.
Nemotron 3 Ultra: a serious open-model tier on your gateway
Nemotron 3 Ultra is a 550-billion-parameter mixture-of-experts model. NVIDIA quotes up to 5× faster inference and roughly 30% cheaper running cost than the leading proprietary models[12]. It ships alongside the existing Nemotron family and two regional datasets, Nemotron-Personas-Vietnam and Nemotron-Personas-El-Salvador, which signal NVIDIA's continued push into sovereign-AI building blocks.

For your gateway, this is exactly the kind of model to add as a price-and-quality tier in your provider mix. Sarmalink-AI's adapter pattern means a single config line for an OpenAI-compatible Nemotron endpoint. Do not migrate. Add.
Agent Toolkit, OpenShell, NemoClaw: NVIDIA's enterprise agent stack
NVIDIA unveiled three pieces that together form a serious enterprise-agent runtime story. NemoClaw is the "blueprint and installer" for local autonomous agents on DGX Spark, with secure runtime support for what NVIDIA calls Hermes Agent. OpenShell is the secure runtime itself, with sandboxes, policy enforcement, and centralised governance. Agent Toolkit is the full-stack runtime for building, deploying, and securing autonomous agents in enterprise environments[1].
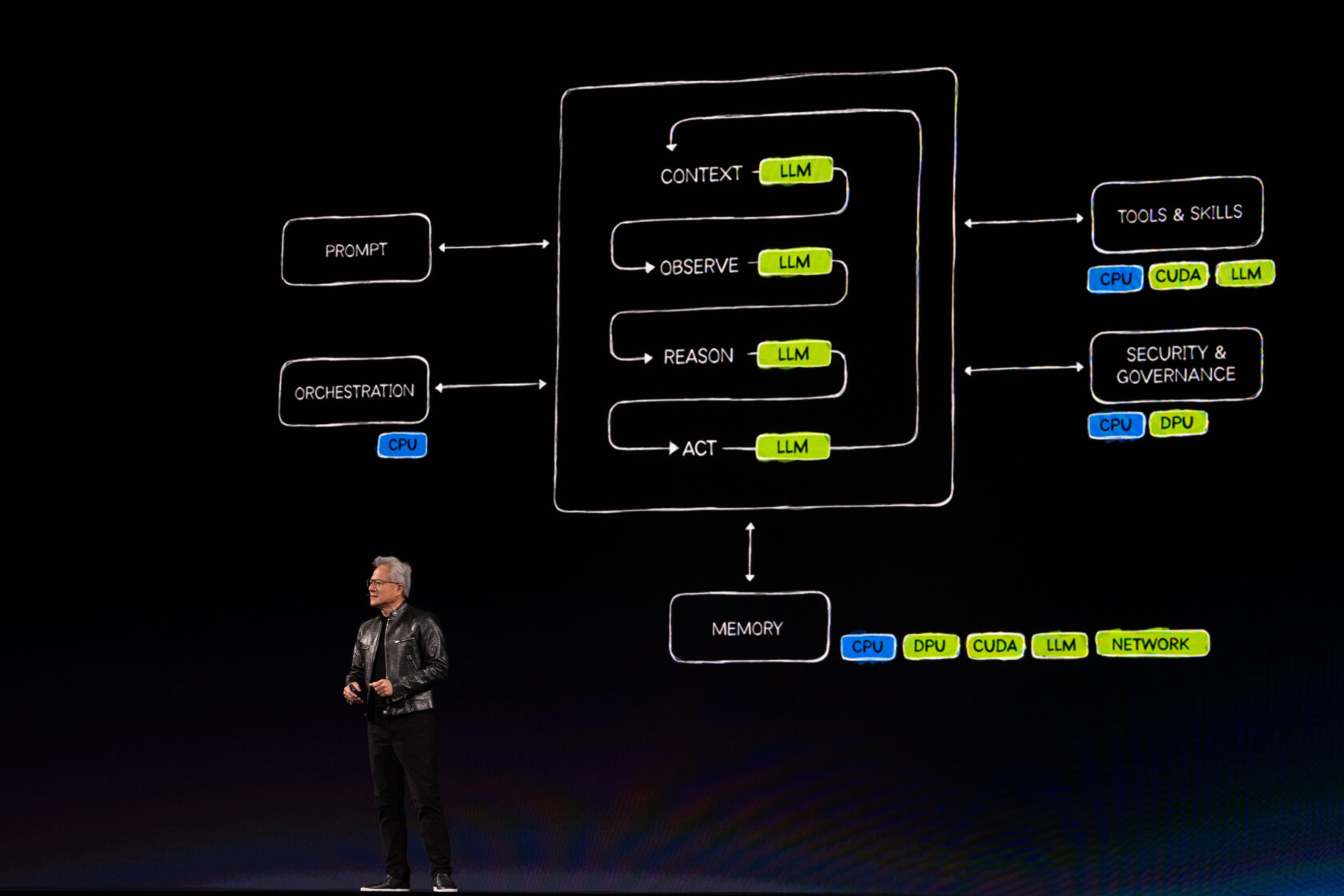
The open-source-AI-engineer take is short. Skip Agent Toolkit and OpenShell unless your customer is asking for them. The open-source way is MCP servers in your skill bus, durable journaled workflows in agent-orchestrator, and your own gateway. NVIDIA's runtime story is genuinely strong if you are buying enterprise; it is not what you would build if you are starting fresh on open-source primitives.
NVIDIA AI for Media: the surprise package
NVIDIA quietly shipped a media stack that is more practical than any other broadcaster-targeted vendor product I have seen at this kind of show. LipSync synchronises on-screen lip movements to dubbed audio in real time across multiple languages. Active Speaker Detection tracks the speaker in real time inside a multi-source video feed. RTX Video Super Resolution and RTX Video Frame Generation cover upscaling and smoothing. The Synthetic Video Detector identifies AI-generated video at roughly 92% accuracy in roughly 22 milliseconds, which is the most quotable number on the day for newsrooms and content platforms[1].

If you build for broadcasters or platforms, you should at least read the NVIDIA AI for Media product page. None of this is open source today, but the primitives are good enough that the open-source community will likely build reference adapters within the year.
Networking: Spectrum-X Photonics, Groq 3 LPX, and the AI factory architecture
Two pieces of network silicon mattered. Spectrum-X Ethernet Photonics is NVIDIA's co-packaged-optics switching fabric, with 200Gb/s SerDes targeted at million-GPU AI factories. NVIDIA quotes 5× better power efficiency, 5× longer AI uptime, and 1.3× faster deployment versus the prior generation[1]. Groq 3 LPX is the low-latency inference processing unit that sits inside Vera Rubin systems; NVIDIA quotes 35× higher throughput per watt for trillion-parameter models[1].

These are not parts that an indie buys. They are parts that change the cost-per-hour on the parts you do buy. The right way to read this is: the AI factory's unit economics moved again, in NVIDIA's favour, in NVIDIA's customers' favour, and through them in your favour.
What this means for the open-source AI engineer's roadmap
Pulling the strands together. Six concrete decisions for the next six months.
- Plan your provider rotation for late summer. When the Vera Rubin hour on your preferred third-party cloud drops below the H100 hour you are paying for, rotate. The savings are larger than most product teams realise.
- If you build voice loops or local-first assistants, start designing for DGX Spark / DGX Station class machines now. The 30B-and-up local brain is now realistic on Windows as well as Linux.
- If you self-host inference on NVIDIA hardware, adopt TensorRT-LLM[7]. Stop hand-rolling against vanilla CUDA. The toolchain has matured.
- Add Nemotron 3 Ultra to your gateway as a tier. ~30% cheaper than leading proprietary models, OpenAI-compatible behind your gateway. No migration needed.
- Read the Cosmos 3 developer guide once. The MCP-shape skill bus plus simulation-first plus brain-agnostic pattern it crystallises is where embodied agents are going.
- Treat Agent Toolkit, OpenShell, NIM[8] as additional upstreams behind your existing gateway, not destinations. If you already have an OpenAI-compatible router, none of these requires a migration.
Where my own work intersects all of this
A brief honest map. forge-infer[13] is my minimal Rust LLM inference server with paged KV cache and speculative decoding. Computex confirmed that paged KV plus continuous batching plus speculative decoding is the production-grade NVIDIA baseline. The differences are throughput at scale and ecosystem maturity, not architecture.
Sarmalink-AI[14] is my multi-provider AI gateway. It is OpenAI-compatible by design. NIM, Nemotron 3 Ultra, Together, OpenAI, Anthropic, Google, your local Ollama, all sit behind the same gateway with adapter modules. Computex's announcements add a tier; they do not change the gateway design.
voice-agent-starter[15] is my sub-second WebRTC voice loop reference. Computex's RTX Spark and DGX Station announcements give the local-first build target a credible Windows path for the first time.
echo[16] is the local-first cross-platform AI assistant that ties it together. It ships publicly on 1 July 2026. The brain router across Claude Code, Codex CLI, Gemini CLI, Ollama, and LM Studio means that whichever way Computex pushed your hardware decision, echo runs on top.
Closing
Computex 2026 was NVIDIA setting the next eighteen months of the AI infrastructure conversation, as it usually is. The story was a generational rack-scale step, a credible personal-compute push on Windows, a serious robotics moment, a strong open-model tier, and a relentless line on inference economics. None of it changes the open-source AI engineer's strategy. All of it changes the costs and the options.
The repos are open. The code is honest. Email me at hello@sarmalinux.com if any of this is useful or wrong.
---
A note on this post
Product names, the specific numbers in the comparison table and the text descriptions are sourced from NVIDIA's own blog post for GTC Taipei at Computex 2026 and their press materials. Every image is hot-linked from NVIDIA's own publication URL and labelled "Image courtesy of NVIDIA". Image and product copyright belongs to NVIDIA Corporation. The opinions and the "what an open-source AI engineer does about this" interpretation are mine. If you spot a specification that does not reproduce against NVIDIA's official material, email me at hello@sarmalinux.com and I will fix or remove it.
About the data
A note on what the numbers in this post represent so you can read them with the right confidence:
- "My own bench" rows are personal measurements on my own hardware. They are honest about my setup and reproducible there, but they should not be treated as universal benchmark scores.
- Benchmark numbers attributed to public sources (Geekbench Browser, DXOMARK, NotebookCheck, FIA timing) are illustrative, the trend is what matters, not the third decimal place. Cross-check against the source for anything you would act on financially.
- Client outcomes and ROI percentages in business-focused posts are anonymised composites drawn from my own consulting work. Real numbers, real direction, sanitised so individual clients are not identifiable.
- Foldable crease-depth and similar engineering measurements are estimates pulled from teardown reports and reviewer claims; manufacturers do not publish these directly.
- Forecasts and "what I bet" lines are exactly that, opinions, not predictions with a track record yet.
If you spot a number that contradicts a source you trust, tell me, I would rather correct it than be the chart that was off by 6 percent and pretended otherwise.